2021. 11. 11. 08:08 ㆍ개발 이야기/python

논문에 필요한 연구를 하는 와중 python pandas dataframe을 사용하는데, 특정 행 이하의 모든 데이터를 제거해야 하는데 pandas를 개발에 많이 사용해보지 않은 탓에 조금 헤멨는데요 .. 저같은 분이 계실까 남겨봅니다.
csv 파일을 이용해 거시경제 정보와 주가 정보를 핸들링하는데 아시겠지만 회사의 주가정보 보다 거시경제 정보가 당연히 많기 때문에 회사의 주가 정보 분석을 위한 데이터 포맷을 만들기에는 주가정보의 가장 과거 데이터보다 더 과거의 거시경제 정보는 쓰레기 정보가 됩니다.
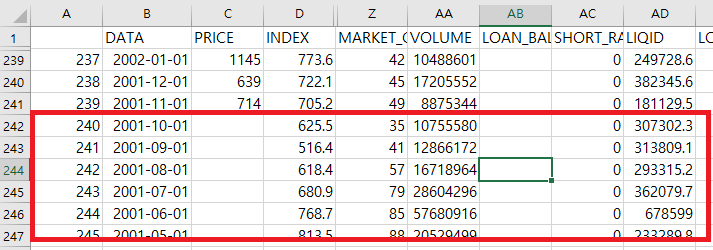
주가 정보인 PRICE 보다 더 과거 거시경제 정보는 행을 맞춰서 반듯하게 만들다보니, pandas 특정 행 이하 제거 로직을 찾아보게 되었습니다.
순서는
- csv 파일을 pandas로 읽은 후
- nan(Not a Number) 행을 제외한 PRICE의 행의 길이를 파악
- PRICE 행의 길이 이후의 dataframe 제거
pandas의 drop 메서드를 이용해서 간단하게 구현했는데요. dropna() 메서드를 사용하면 nan 값을 제거하게 되고 shape으로 행의 길이를 알아낸 후 -1을 해줍니다.
csv = pd.read_csv(root_path + "/" + dirs + "/" + file, index_col=0)
price_len = csv["PRICE"].dropna().shape[0] - 1이후가 중요한데요. 제가 찾아본 바로는 특정 행 이후를 한번에 지워주는 메서드를 찾지 못해서 앞서 구한 price_len과 dataframe의 index와 비교에 price_len보다 큰 값을 담은 index dataframe을 만들어줍니다.
indexNames = csv[csv.index > price_len].index
디버깅 해보면 다음과 같은 dataframe이 생성된 것을 확인할 수 있는데요. 이제 이 변수를 이용해 drop 메서드에 넣어줍니다. (inpalce=True를 꼭 넣어주셔야합니다)
csv.drop(indexNames, inplace=True)
csv.to_csv("저장경로")이렇게 price 값이 끝나는 행 이후의 거시경제 데이터를 지울 수 있었습니다. 결과는 다음과 같습니다.

이상, 저 처럼 귀중한 시간 버리지 마시길 바라며.
'개발 이야기 > python' 카테고리의 다른 글
| Pytest로 자동화된 Python 모듈 테스트 방법 (8) | 2024.11.12 |
|---|---|
| OpenTelemetry Python Asyncio 지원 (0) | 2024.03.30 |
| [회귀분석] COVID-19 확산 지표와 교통 통계량 데이터를 이용한 회귀분석 과정 (0) | 2021.07.04 |
| # anaconda 64bit 설치 후 32bit python 사용하기 (0) | 2020.09.02 |
| 비동기 B2C 서버 구축하기 - Gunicorn, Celery, rabbitMQ (7) | 2019.11.23 |