2019. 8. 18. 19:41 ㆍ개발 이야기/머신러닝(딥러닝)
지난번에 소개했던 wFST 기반의 음성인식 툴 KALDI의 간략한 소개와 함께
설치 방법에 대해서 알아보자!
Kaldi 이름의 유래?
칼디는 원래 커피 식물을 발견한 목사였다고 하네요 ㅎㅎ 재밌는 사실이네요
Kaldi는 C++로 작성되고 라이센스는 Apache License v2.0!!가 부여된
음성 인식 용 툴킷입니다!
이 Kaldi 프로젝트의 역사는 굉장히 긴데요!
벌써 10년이나 됬다고 합니다
Kaldi began its existence in the 2009 Johns Hopkins University workshop cumbersomely titled "Low Development Cost, High Quality Speech Recognition for New Languages and Domains"
존스 홉킨스 대학 워크숏에서 시작됬는데요
굉장히 긴 역사를 자랑하는 프로젝트네요 ㅎㅎ
이것과는 다르게 이 칼디가 등장함으로써
음성인식 분야가 정말 활발해졌고!
기능 또한 엄청나게 발전을 이뤘기 때문에 정말 대단한! 프로젝트라고 생각이 됩니다.
자 그럼 본격적으로 Kaldi를 설치하고 빌드해보도록 하겠습니다
먼저 우리는 한국사람이기 때문의 칼디 툴을 이용한
한국어 프로젝트 zeroth 프로젝트 를 목표로! 셋팅을 할껀데요
기본적인 하드웨어 스펙이 필요합니다.
저도 처음에는 단순 VM웨어로 아 이게 뭐 얼마나 리소스를 먹겠어? 라는 생각으로 시도를 했었는데
상당히 많이 끊어먹고, 다시하고, 맨땅하고 하다가 알게된 최소한의 스펙이 있더라구요!
그 기준으로 말씀드리면!
OS : Linux(칼디는 윈도우를 지원하지 않아요)
RAM : 음성 인식률에 따라 다르지만 최소 60GB 권장
(제로스 프로젝트를 러닝 시킬때 이부분에 대해서 설명할게요)
HDD : 500GB
(하드가 500GB인 러프하게 잡았구요
러닝에 사용되는 음성파일이 많은 경우!!
음성파일의 용량 X 5 정도로 생각하시면 됩니다)
그리고 !!
그래픽 카드는 좋을 수록 좋은데요
최소 1060 6GB 짜리를 끼워주는 편이 좋습니다
자 그럼 기본적으로 영어 음성인식 버전으로 셋팅을 시작하겠습니다!
기본적으로 설치해야하는 패키지!
apt-get update && apt-get install -y \
autoconf \
automake \
bzip2 \
g++ \
git \
gstreamer1.0-plugins-good \
gstreamer1.0-tools \
gstreamer1.0-pulseaudio \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-base \
gstreamer1.0-plugins-ugly \
libatlas3-base \
libgstreamer1.0-dev \
libtool-bin \
make \
python2.7 \
python3 \
python-pip \
python-yaml \
python-simplejson \
python-gi \
subversion \
wget \
build-essential \
python-dev \
sox \
zlib1g-dev && \
apt-get clean autoclean && \
apt-get autoremove -y && \
pip install ws4py==0.3.2 && \
pip install tornado==4.5.3 && \
ln -s /usr/bin/python2.7 /usr/bin/python ; ln -s -f bash /bin/sh코드를 쭉! 복사에서 터미널에 넣으시면 되요 !
(단순 패키지 설치 및 파이썬 모듈 설치 내용입니다)
여기서 핵심인 부분은 gstreamer 패키지인데요!
이 패키지는 멀티미디어를 다룰 때 쓰는 응용프로그램 이라고 이해하시는 편이 좋습니다.
자세한 설명은 https://gstreamer.freedesktop.org/
이 부분에서 참고하시구요!
그리고 저기 있는 토네이도는 쉽게 설명하면 파이썬 비동기 웹 프레임워크인데요
영어 음성인식 테스트할때 사용되는 부분이라
나중에 개인적으로 개발하셨을 경우에는 사용하지 않으셔도되요
그리고 cuda를 설치해줄 껀데요! cuda 설치는
developer.nvidia.com
해당 URL을 통해서 설치해주시면 됩니다!
그리고 가장 키포인트가 있는데요!
CUDA는 호환되는 GCC 버전이 존재합니다
우리가 보통 사용하게 될 9, 10 ,10.1 버전은
gcc-7, g++-7 버전을 설치해서 이용하면됩니다!
설정 방법은
//// cuda 설치 하고 지원하는 gcc, g++ 7.4이하 버전 꼭 맞춰놔야함///
sudo apt install gcc-7 g++-7
//// next, link them into your cuda stack///
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda/bin/g++이런식으로 설치 후 심볼릭 링크까지 걸어주시면 됩니다!
예를 위해 /opt 디렉터리에서 셋팅을 진행하겠습니다.
cd /opt
wget http://www.digip.org/jansson/releases/jansson-2.7.tar.bz2 && \
bunzip2 -c jansson-2.7.tar.bz2 | tar xf - && \
cd jansson-2.7 && \
./configure && make && make check && make install && \
echo "/usr/local/lib" >> /etc/ld.so.conf.d/jansson.conf && ldconfig && \
rm /opt/jansson-2.7.tar.bz2 && rm -rf /opt/jansson-2.7jansson을 설치하고 make를 이용해 빌두 하고 설정해주고 다운로드한 압축파일 지우는 과정
다시
cd /opt
git clone https://github.com/kaldi-asr/kaldi.git
git clone 은 형상관리 오픈소스인 git을 이용해 소스코드를 가져오는 명령어인데요
쉽게 kaldi 소스코드를 다운로드하는 거라고 생각하시면 됩니다!

완료하면 이렇게 디렉터리가 생성되고 그 안에는 소스코드가 있어요
cd /opt/kaldi/tools && \
make && \
./install_portaudio.sh && \
cd /opt/kaldi/src && ./configure --shared && \
sed -i '/-g # -O0 -DKALDI_PARANOID/c\-O3 -DNDEBUG' kaldi.mk && \
make depend && make && \
cd /opt/kaldi/src/online && make depend && make && \그 다음은 요렇게 쭉 복붙하시면 portaudio 설치후 src 하위의 디렉터리들
그리고 src/online 하위에 파일들이 빌드되요!
여기서 팁을 드리자면
make 명령어는 -j 옵션을 통해서
컴파일 속도를 더 빠르게 할 수 있는데요
이 부분은 한번 검색을 통해 알아보시면 좋습니다!
이어서!
cd /opt/kaldi/src/gst-plugin && make depend && make && \
cd /opt && \
git clone https://github.com/alumae/gst-kaldi-nnet2-online.git && \
cd /opt/gst-kaldi-nnet2-online/src && \
sed -i '/KALDI_ROOT?=\/home\/tanel\/tools\/kaldi-trunk/c\KALDI_ROOT?=\/opt\/kaldi' Makefile && \
make depend && make && \
cd /opt && git clone https://github.com/alumae/kaldi-gstreamer-server.git
git clone https://github.com/jcsilva/docker-kaldi-gstreamer-server.git
cd docker-kaldi-gstreamer-server
chmod +x /opt/start.sh && \
chmod +x /opt/stop.sh 여기서 관건은 sed 명령어로 makefile 의 내용을 변경하는 부분인데요
kaldi를 git으로 다운로드 한 위치를 넣어주시면 됩니다
\/opt\/kaldi 인 이유는 거기에 칼디를 설치해서!
여기까지 따라오셨으면 kaldi-gstreamer-server가 동작하게 됩니다!
그럼 이제 영어 음성인식에 사용할 데이터를 다운로드 하겠습니다.
mkdir /opt/models
cd /opt/models
wget https://phon.ioc.ee/~tanela/tedlium_nnet_ms_sp_online.tgz
tar -zxvf tedlium_nnet_ms_sp_online.tgz
wget https://raw.githubusercontent.com/alumae/kaldi-gstreamer-server/master/sample_english_nnet2.yaml
find /opt/models/ -type f | xargs sed -i 's:test:/opt:g'
sed -i 's:full-post-processor:#full-post-processor:g' /opt/models/sample_english_nnet2.yaml
다운로드 하면 아래와 같이 파일이 작성되는데요
------ 경로 설정 config 파일( /opt/models/english/tedlium_nnet_ms_sp_online/ )----------
-rw-r--r-- 1 bourbonkk bourbonkk 629 11월 5 16:59 ivector_extractor.conf
-rw-r--r-- 1 bourbonkk bourbonkk 670 4월 7 2015 mfcc.conf
-rw-r--r-- 1 bourbonkk bourbonkk 95 4월 7 2015 online_cmvn.conf
-rw-r--r-- 1 bourbonkk bourbonkk 319 11월 5 16:59 online_nnet2_decoding.conf
-rw-r--r-- 1 bourbonkk bourbonkk 35 4월 7 2015 splice.conf
-rw-r--r-- 1 bourbonkk bourbonkk 95 4월 7 2015 online_cmvn.conf
bourbonkk@bourbonkk-VM:/opt/models$ cat ./sample_english_nnet2.yaml
# You have to download TEDLIUM "online nnet2" models in order to use this sample
# Run download-tedlium-nnet2.sh in 'test/models' to download them.
use-nnet2: True
decoder:
# All the properties nested here correspond to the kaldinnet2onlinedecoder GStreamer plugin properties.
# Use gst-inspect-1.0 ./libgstkaldionline2.so kaldinnet2onlinedecoder to discover the available properties
use-threaded-decoder: true
model : /opt/models/english/tedlium_nnet_ms_sp_online/final.mdl
word-syms : /opt/models/english/tedlium_nnet_ms_sp_online/words.txt
fst : /opt/models/english/tedlium_nnet_ms_sp_online/HCLG.fst
mfcc-config : /opt/models/english/tedlium_nnet_ms_sp_online/conf/mfcc.conf
ivector-extraction-config : /opt/models/english/tedlium_nnet_ms_sp_online/conf/ivector_extractor.conf
max-active: 10000
컨피그 파일에 위와 같이 모델 파일의 경로를 넣어주시면 끝입니다!
이제 실행 시켜 보겠습니다!
/opt/start.sh -y /opt/models/sample_english_nnet2.yaml
이제! 영어 음성 인식을 시작할 수 있습니다.
이런 명령어 들로 테스트를 진행 할 수도 있구요!
wget https://raw.githubusercontent.com/alumae/kaldi-gstreamer-server/master/kaldigstserver/client.py -P /tmp
wget https://raw.githubusercontent.com/jcsilva/docker-kaldi-gstreamer-server/master/audio/1272-128104-0000.wav -P /tmp
wget https://raw.githubusercontent.com/alumae/kaldi-gstreamer-server/master/test/data/bill_gates-TED.mp3 -P /tmp
python /tmp/client.py -u ws://localhost:8080/client/ws/speech -r 32000 /tmp/1272-128104-0000.wav
python /tmp/client.py -u ws://localhost:8080/client/ws/speech -r 8192 /tmp/bill_gates-TED.mp3
이렇게 셋팅을 한 후

음성인식이 제대로 되는지 테스트를 할 수 있는 코네레 ? 앱을 다운로드 받으신 후에
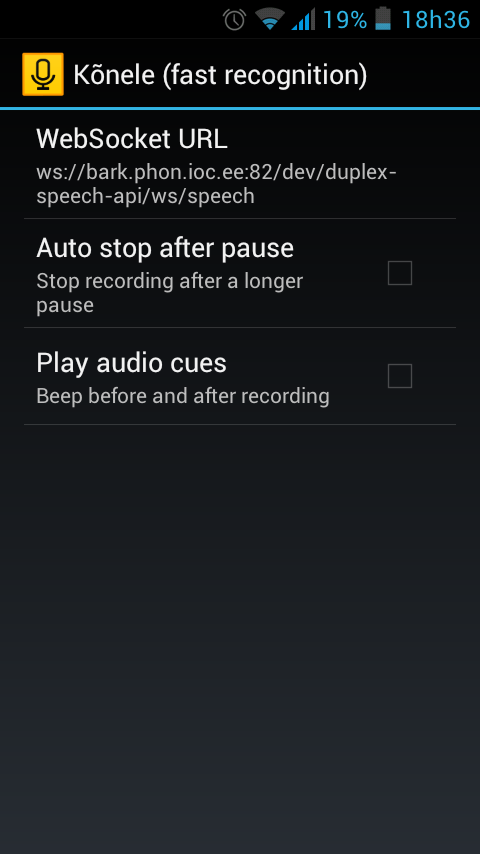

IP를 설정해 준 후!

노란색 버튼을 누르고 말을 하면!!
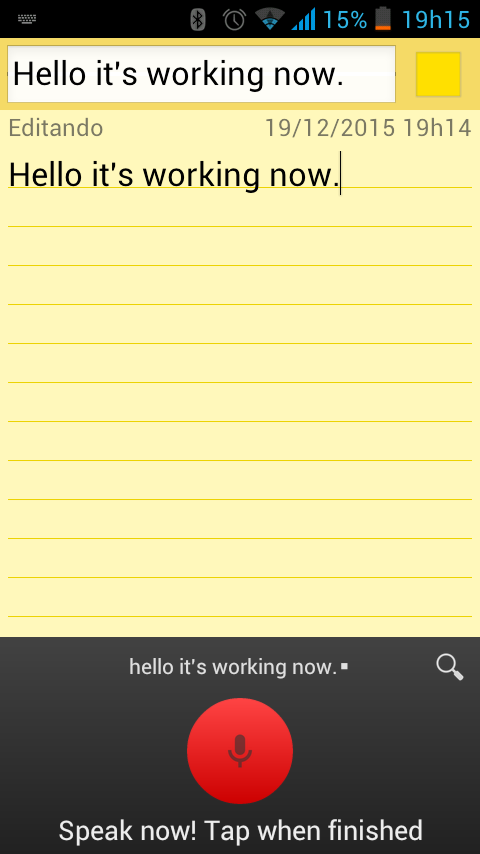
요렇게 인식이 됩니다!
이런식으로 테스트도 가능합니다!
다음은 한국어 음성인식을 할 수 있는 zeroth 프로젝트를 셋팅하고 한국어를 인식시켜 보도록 하겠습니다!
'개발 이야기 > 머신러닝(딥러닝)' 카테고리의 다른 글
| #Back to basic 머신러닝이란? (0) | 2019.09.29 |
|---|---|
| #5 음성인식 노이즈 제거 (16) | 2019.09.20 |
| #4 음성인식 KALDI 툴을 이용한 한국어 음성인식(zeroth project) (69) | 2019.08.18 |
| #2 음성인식 이해 (0) | 2019.08.10 |
| #1 음성인식 기초(오디오 파일의 구조) (0) | 2019.08.10 |