2020. 3. 17. 00:37 ㆍ개발 이야기/오픈소스
안녕하세요 해커의 개발일기 입니다.
오늘은 NoSQL DBMS 중 높은 확장성과 고 가용성을 자랑하는 Casandra DBMS를 소개하고,
scale out 해 cluster를 구성하는 방법을 알아보도록 하겠습니다.

※ 스케일 아웃(scale out) : 기존의 서버와 같은 사양 또는 비슷한 사양의 서버 대수를 증가시키는 방법으로 처리 능력을 향상하는 것
카산드라의 데이터 모델은 최상위 논리적 Data 저장소인 Keyspace 아래 Table이 있고 Table은 다수의 Row들로 구성되며 Row는 Key-Value로 이루어진 Column들로 구성됩니다. 하나의 Row는 여러 개의 Column을 가질 수 있고 여기에는 SET, LIST, MAP 등의 형태도 저장이 가능합니다.
이 카산드라는 CQL(Cassandra Query Language)가 제공되어 기존에 RDBMS를 사용하는 사람이면 어렵지 않게 다가갈 수 있습니다. 그리고 카산드라가 고 가용성(High Availability)과 높은 확장성(scalability)을 가질 수 있는 이유는 전염병 확산 방식에 기반한 Gossip 프로토콜을 통해 Ring 구조를 가진 노드들을 일관성 있게 만들어주기 때문입니다.


※ Gossip 프로토콜이란? Cluster 안에 노드끼리 정보를 공유하기 위해 만들어진 프로토콜
카산드라에는 Snitch라는 개념이 있습니다. Snitch는 클러스터가 어떻게 구성되어 있는지 노드들은 어떤 DC(Data Center)와 Rack에 있는지 논리적으로 구분해 node 간의 topology를 카산드라에게 알려주기 위한 방법입니다.
※ 이번 블로그에서는 product에 권장되는 Snitch인 GossipingPropertyFileSnitch를 이용해 클러스터를 구성해보도록 하겠습니다.
아래의 URL에서 다운로드하실 수 있으며 실행방법은 조금씩 다르지만 config는 같기 때문에 어렵지 않게 따라 해 보실 수 있습니다. https://cassandra.apache.org/download/
Download
Downloading Cassandra Latest version Download the latest Apache Cassandra 3.11 release: 3.11.6 (pgp, sha256 and sha512), released on 2020-02-14. Older supported releases The following older Cassandra releases are still supported: Apache Cassandra 3.0 is su
cassandra.apache.org
다운로드를 한 후 압축을 풀면 아래와 같은 모습의 디렉터리가 있습니다.

./bin 에는 cqlsh와 cassandra 바이너리, node 구성에 사용되는 nodetool 바이너리 등이 있습니다.

./conf 에는 이름에서 짐작할 수 있듯 설정 파일들이 있습니다.
먼저 노드들의 구성을 위해서는 ./conf/cassandra.yaml 파일에 설정을 변경해 node의 대장인 seed와 각 node의 ip 설정을 해줍니다.
vim ./conf/cassandra.yaml
cluster_name: 'Test Cluster' # 10번째 line cluster의 이름
-seeds: (SEED 서버 ip)
listen_address: 각 서버 ip
rpc_address: 각 서버 ip
broadcast_rpc_address: 각 서버 broadcast ip(255로 끝남)
endpoint_snitch: GossipingPropertyFileSnitch



이렇게 node가 되는 각 서버에서 cassandra.yaml을 수정해 줍니다. 그리고 ./conf/cassandra-rackdc.properties 파일에서 dc(datacenter)와 rack을 설정해줍니다. 여기서 참고사항이 있습니다.
이 부분은 해석하기에 따라 조금 의견이 다를 수 있습니다. 제가 해석하기에는 위와 같습니다. 원문을 확인하시고 싶으신 경우 아래의 URL에서 확인해주세요
https://docs.datastax.com/en/archived/cassandra/3.0/cassandra/architecture/archSnitchesAbout.html
저의 경우 4개의 node를 셋팅했습니다. 1개의 DC있고 참고사항에 따라 rack을 모두 다르게 설정했습니다.
vim ./conf/cassandra-rackdc.properties
# These properties are used with GossipingPropertyFileSnitch and will
# indicate the rack and dc for this node
dc=dc1
rack=rack2
# rack = rack1, rack2, rack3, rack4
클러스터를 구성하기 위한 설정은 모두 끝났습니다. 이제 각 서버에서 cassandra 바이너리를 실행시켜보겠습니다.
# SimpleSnitch 실행 시
./bin/cassandra -f -R -Dcassandra.ignore_dc=true # SimpleSnitch
# GossipingPropertyFileSnitch 실행 시
./bin/cassandra -f -R -Dcassandra.ignore_dc=true -Dcassandra.ignore_rack=true # GossipingPropertyFileSnitch
4 개의 노드에서 cassandra 바이너리를 모두 실행시켜주면 자동으로 Gossip 프로토콜로 클러스터 구성이 완료됩니다.

4개의 쉘을 띄워 놓고 gossip으로 바로바로 연동되는 것을 확인해봤는데요. 컨피그 몇 줄 변경하고 간단하게 cluster를 구성할 수 있었습니다.
자 이제 정상적으로 node가 연동되었는지 확인하기위해 ./bin 디렉터리에 있던 nodetool을 이용해 보겠습니다.

정상적으로 클러스터 구성이 된 경우에 위와 같이 출력되는 것을 확인할 수 있습니다.
그렇다면 노드가 필요 없어져서 노드를 종료한다면? 클러스터는 정상적으로 노드들이 모두 UP 상태가 아니라고 판단하기 때문에 에러가 발생하게 됩니다. 이런 경우에는 에러가 발생한 node를 제거해주어야 하는데요. nodetool을 이용해 에러가 발생한 노드를 제거해보도록 하겠습니다.

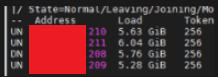
30.208 노드의 state가 DN으로 다운된 것을 확인할 수 있습니다.
node 제거 시에는 nodetool을 removenode 옵션을 이용합니다. 아래의 그림을 통해 노드가 제거되고 정상적으로 제거된 경우 어떤 결과가 출력되는지 확인해보겠습니다.
./bin/nodetool removenode Host ID
./bin/nodetool status

이렇게 정상적으로 DN state였던 208 노드를 제거해 정상적으로 3개의 노드로 클러스터를 구성했습니다.
여기까지 cassandra의 확장성을 이용할 수 있는 cluster 구성 방법이었습니다. cassandra는 정말 손쉽게 cluster를 구성하고 scale out을 진행할 수 있도록 편리하게 되어있는데요. 혹시 NoSQL을 검토 중이시라면 이 카산드라도 컴토를 한번 해보시기를 추천해드립니다.

사실 저도 요즘 cassandra의 성능에 대해 많이 테스트를 해보고 있는데요. 쉽게 찾아볼 수 있는 node 증가에 따른 선형적인 TPS 증가 그래프는 제가 하니까... 잘 안 나왔습니다. 물론 제가 잘 사용하지 못하는 게 분명할 테지만 node 증가에 따라 드라마틱한 성능 증가는 많이 테스트해보시고 다양하게 튜닝 시도를 해보셔야 할 것 같습니다. 이상입니다.
'개발 이야기 > 오픈소스' 카테고리의 다른 글
| # Git 사용하기, conflict 처리하기, branch 만들기 (0) | 2020.05.05 |
|---|---|
| # 오픈소스 OpenTracing - Jaeger (0) | 2020.03.25 |
| # Container Orchestration - 쿠버네티스(kubernetes - K8s) (0) | 2020.03.14 |
| # 오픈소스 모니터링 시스템 Prometheus, 시각화 소프트웨어 Grafana (0) | 2020.03.06 |
| # Docker 소개 (0) | 2020.03.04 |