2020. 3. 25. 21:54 ㆍ개발 이야기/오픈소스
안녕하세요. 해커의 개발일기 입니다.
오늘은 마이크로 서비스 아키텍처를 사용하여 구축된 응용 프로그램을 프로파일링하고 모니터링하는데 사용하는
Distributed Tracing 분산 추적 기술에 대해서
알아보는 시간을 갖도록 하겠습니다.

분산 추적 기술은 근래 해외에서 많이 사용되고 국내에서도 점차적으로 도입하고 있는 것으로 알고 있습니다. 왜? 분산 추적 기술을 사용할까요? 분산 추적 기술이라는 것은 MSA 구조에 최적화되어 어느 부분에서 병목현상이 발생하는지, 어느 부분에서 장애가 발생하는지 위치와 성능 저하의 원인을 정확히 판단하는데 도움을 줄 수 있는 기술입니다.
OpenTracing은 무엇일까요?
OpenTracing은 어떤 프로그램이 아닙니다. OpenTracing 홈페이지에 가면 언어별 가이드가 존재합니다.
https://opentracing.io/guides/
OpenTracing Guides
Welcome to the OpenTracing Guides! Guides are “how-to manuals” for using OpenTracing. Unlike the Overview, guides are language specific, describing common scenarios and use cases that you many encounter in that environment.
opentracing.io
하지만 많은 부분 개발자가 추가해주어야 사용할 수있고 그저 가이드라인 수준의 소스코드를 제공해주고 있습니다.
OpenTracing은 표준이 아닙니다. OpenTracing을 만든 CNCF (Cloud Native Computing Foundation)는 공식 표준 기관이 아닙니다. OpenTracing API 프로젝트는 분산 추적을 위해 보다 표준화된 API 및 계측을 작성하려고 노력하고 있습니다. OpenTracing은 API 사양, 이 사양을 구현한 프레임워크 및 라이브러리 및 프로젝트 문서로 구성됩니다.
정리하면, 분산 추적 기술을 개발하기에 필요한 개념과 사양을 정리해놓은 프로젝트라고 할 수 있을 것 같습니다.
Distributed Tracing: A Mental Model
대부분의 트레이싱을 위한 Mental Model은 Google의 Dapper 논문에서 비롯되는데 OpenTracing은 이 논문과 비슷한 명사와 동사를 사용합니다.
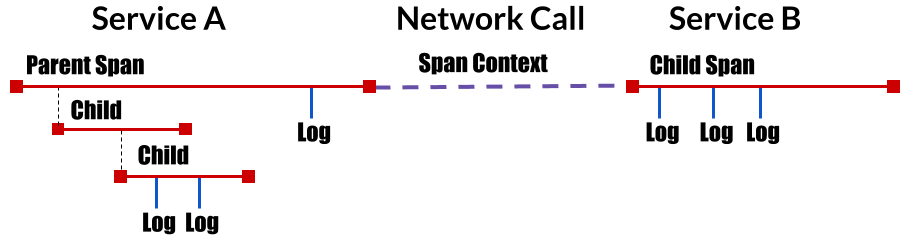
trace : 분산 시스템을 통해 이동하는 트랜잭션에 대한 설명
span : 분산 시스템에서 수행된 개별 작업 단위를 나타내는 분산 추적의 기본 timeline block
- 작업 명
- 시작 타임 스탬프 및 종료 타임 스탬프
- 키 : 값 범위 태그 세트
- 키 : 값 범위 로그 세트
- SpanContext
Span Context : 네트워크를 통해 또는 메시지 버스를 통해 서비스를 서비스로 전달할 때를 포함해 분산 트랜잭션에 수반되는 추적 정보
- 추적 내의 고유 범위를 참조하기 위한 구현 종속 상태
- 즉, 추적 프로그램의 spanID 및 traceID 정의 구현
Example Span:
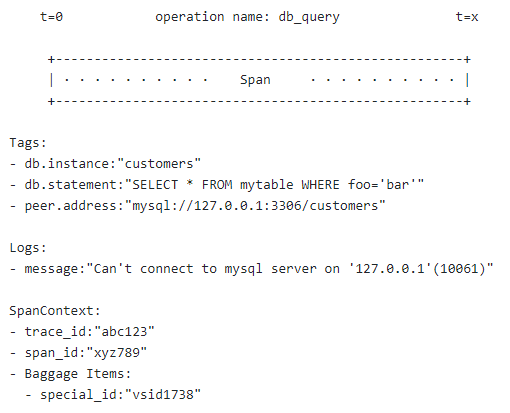

이런 개념에 입각해 OpenTracing를 구현해 놓은 몇 가지의 분산 추적 시스템이 있지만, 그중 Jaeger라고 하는 분산 추적 시스템에 대해 알아보도록 하겠습니다. Jaeger는 Uber Technologies에서 오픈 소스로 출시한 분산 추적 시스템으로 아래와 같은 기능이 포함되어 마이크로 서비스 기반 분산 시스템을 모니터링하고 문제를 해결하는 데 사용됩니다.
- 분산 컨텍스트 전파
- 분산 트랜잭션 모니터링
- 근본 원인 분석
- 서비스 의존성 분석
- 성능 / 지연 시간 최적화
다양한 언어와 스토리지를 제공하기 때문에 기업마다 사용하고 있는 언어로 유연한 대응을 할 수 있습니다.
- OpenTracing 호환 데이터 모델 및 계측 라이브러리
- Golang, Java, node, python, C++
- 개별 서비스 / 엔드 포인트 확률로 일관된 선행 샘플링 사용(샘플링을 통해 중복된 trace 처리 간소화)
- 다중 스토리지 백엔드 : Cassandra, Elasticsearch, in memory
이 외에도 커다란 서비스를 대응하기 위해 Message Queue인 kafka도 사용할 수 있습니다.
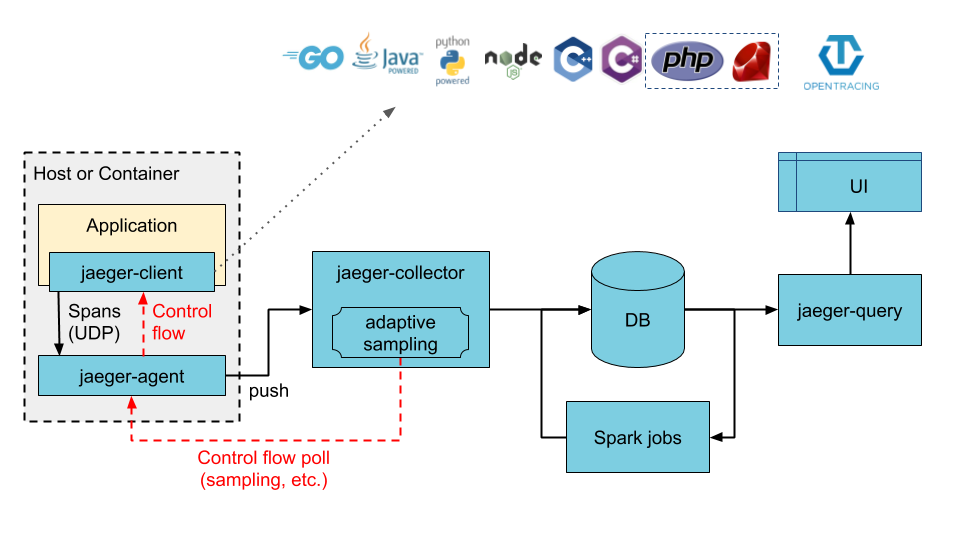
Application에서 나오는 Span 데이터를 jaeger-client가 UDP를 이용해 가볍게 jaeger-agent로 전달을 하고 전달받은 jaeger-agent는 jaeger-collector에게 전달을 하고 jaeger-collector는 이 데이처를 DB에 적재해 줍니다. adaptive sampling에 대해서는 조만간 따로 글을 작성해 보겠습니다.
이러한 아키텍처를 가지고 있고 손쉽게 DB를 늘리고 줄이 고를 할 수 있으며, 손쉽게 agent를 붙이고 다양한 시스템의 trace 정보를 수집할 수 있습니다. 시스템이 커서 collector만으로 trace 정보가 쓰이는 속도를 따라갈 수 없다면
jaeger-collector와 DB 사이에 kafka Message Queue를 두고 MQ를 소비하는 jaeger-ingester를 두어 비동기 시스템으로 구현해 더욱 유연한 대응을 할 수 있습니다.

이미 구현되어 있는 UI를 통해서도 확실한 tracing이 가능하며 오픈 소스이기 때문에 기업에서 사용하는 UI 형태로 다양하게 커스터마이징이 가능한 장점을 가지고 있습니다.

trace 정보를 간략하게 볼 수도 있지만 실제 어디서 바틀넥이 발생하는지 어느 부분에서 장애가 발생하는지 조금 더 상세한 화면에서 확인할 수 있습니다.

이미 구축한지 오래되고 최적화된 시스템에는 다소 필요가 없어 보일 수 있지만, 특정 서버의 노후화라든지, 고장으로 인한 장애. 네트워크 구간에서의 장애 등 시스템의 문제를 아주 visible하게 확인할 수 있습니다. 이미 docker 형태로 이미지가 존재해 아주 손쉽게 설치가 가능하고 조금의 스터디는 당연히 필요하겠지만 투자 시간 대비 업무 효율이 아주 높을 것으로 보입니다.
개발자는 코딩뿐만이 아닌 시스템의 성능과 전체적인 큰 틀을 볼 수 있어야 한다고 생각합니다. 우리는 이런 오픈소스를 이용해 조금 더 시야를 넓힐 수 있는 기회를 마련할 수 있습니다.
이상으로 OpenTracing과 jaeger에 대한 소개였습니다.
'개발 이야기 > 오픈소스' 카테고리의 다른 글
| # Dockerfile로 임시 빌드 환경 구성하기(Dockerfile 응용하기) (0) | 2020.08.13 |
|---|---|
| # Git 사용하기, conflict 처리하기, branch 만들기 (0) | 2020.05.05 |
| # 오픈소스 분산형 NoSQL DBMS Cassandra(카산드라) (0) | 2020.03.17 |
| # Container Orchestration - 쿠버네티스(kubernetes - K8s) (0) | 2020.03.14 |
| # 오픈소스 모니터링 시스템 Prometheus, 시각화 소프트웨어 Grafana (0) | 2020.03.06 |