2022. 1. 11. 08:29 ㆍ개발 이야기/오픈소스
MSA! 마이크로 서비스 아키텍처는 이제 서비스를 개발하고 운영할 때, 빼 놓고 얘기할 수 없는 아키텍처가 되었습니다. 빠른 배포, 유연한 운영, 대용량 서비스에 적합한 MSA는 기존의 모놀리틱 아키텍처가 작은 서비스 단위로 쪼개지고 컨테이너화 되면서 서버의 입장에서는 다소 복잡한 구조를 가지게 되었는데요. 이런 복잡한 구조를 쉽게 관리해주는 Orchestration 오픈소스가 개발되고 그 중에서도 컨테이너 관리에는 Kubernetes가 글로벌 스탠다드로 되어가고 있습니다. 하지만 이런 복잡한 구조를 관리하다보니 수 많은 서비스들의 리소스 사용량과 같은 것들을 모니터링해주는 Observability 분야도 상당히 활발하게 개발되고 많은 서비스들이 배출되고 있습니다.

Observability 분야의 가장 유명한 오픈소스는 Prometheus와 Grafana가 아닐까 싶습니다. 물론 superset 등과 같은 강력한 툴들이 많이 개발되고 있지만, Prometheus와 Grafana가 사용되고 있는 곳이 압도적으로 많은 것 같습니다. 오픈소스라고 하기에는 너무나 강력한 Grafana를 이용해 유용한 정보를 손쉽고 빠르게 다양한 차트로 구성하여 익숙한 사용자의 경우 수 십분 만에 수 천만원에 가까운 모니터링 제품과 같이 만들어낼 수 있습니다.
하지만, MSA가 지속적으로 발달하고 백엔드는 더욱 복잡한 아키텍처로 구성되고 있습니다. Kubernetes 클러스터의 경우도 하나의 클러스터가 아닌 여러개의 클러스터를 사용하고, Kubernetes 환경과 Non-Kubernetes 환경을 혼합해서 관리하기도 합니다. 이런 경우에는 기존의 Promethus를 가지고 구성하면 각각의 환경에 프로메테우스를 설치하고 각각의 환경의 Port를 별도로 Open해서 grafana와 연동을 하거나 grafana 마저 각각의 환경에 띄어놓아야 하는 번거로움이 있습니다.
이런 경우를 대비해 Prometheus는 remote write 기능을 제공하고 있습니다. 하지만 Prometheus는 최초 개발 당시부터 이런 기능을 설계하고 개발된 것이 아니기 때문에 remote write 기능을 사용해도 WAL(Write Ahead Log)에 time series가 기입되고 이를 remote write하는 곳에 endpoint로 전송하는 구조를 가지고 있으며, 이런 구조는 메모리 사용에 많은 영향을 주고 있습니다.
이런 이유로 아래와 같은 아키텍처로 Prometheus의 remote write를 이용해서 하나의 백엔드에 데이터를 수집하고 관리하는 방법은 널리 사용되고 있지 않습니다.
하지만, 이제는 위에서 언급한 바와 같이 Kubernetes 환경과 Non-Kubernetes 환경, IaaS 환경 등 다양하고 복합적인 환경에서 MSA로 개발된 어플리케이션이 서비스되고 있으며 이런 분야의 Observability는 새로운 시장으로 개척될 것으로 보여집니다.
대안으로, 다양한 환경의 시계열 데이터를 수집하는 아키텍처로 개발된 Clymene를 사용하면 복잡하고 다양한 여러 환경, 여러 시스템의 시계열 데이터를 한 곳에 모아서 Observability 제공할 수 있습니다.
Clymene는 Prometheus의 시계열 데이터 수집 방식과 분산 환경의 서비스 트레이싱 오픈소스인 Jaeger의 아키텍처를 기반으로 개발된 오픈소스입니다. Prometheus의 Service Discovery 기능이 존재해 손쉽게 여러 환경의 시계열 데이터를 수집할 수 있는 Endpoint를 찾아낼 수 있으며, Jaeger의 백엔드 구조를 이용해 강력한 HA(High-Availability) 아키텍처로 구성할 수 있습니다.
시계열 데이터 수집을 담당하는 Clymene-Agent에는 Prometheus의 Serivce Discovery 기능이 있으며, 시계열 데이터를 수집해서 전송할 때 Agent에 적합한 구조(WAL 미사용, scrape only)로 개발되어 Prometheus의 Remote Write 기능과 비교해 리소스 소모량이 상대적으로 적습니다.
Windows exporter를 수집하는 scrape rule을 적용해 성능을 확인해보겠습니다.
Clymene Agent의 scape rule
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
- job_name: 'clymene_windows_exporter'
static_configs:
- targets: [ 'localhost:9182' ]
Prometheus의 Remote write rule(using 8080 port)
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
remote_write:
- url: "http://localhost:9090/api/v1/write"
scrape_configs:
- job_name: "windows_exporter"
static_configs:
- targets: ["localhost:9182"]
데이터 수신용 Prometheus rule(성능 분석용 Clymene_agent, remote_prometheus 비교)(Using 9090 port)
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "clymene_agent"
static_configs:
- targets: ["localhost:15691"]
- job_name: "prometheus_remote_writer"
static_configs:
- targets: ["localhost:8080"]
저장용 Prometheus의 UI에서 확인 시 Prometheus와 Clymene가 전송하는 Windows_exporter 시계열 데이터가 정상적으로 저장되고 있는 것을 알 수 있습니다.
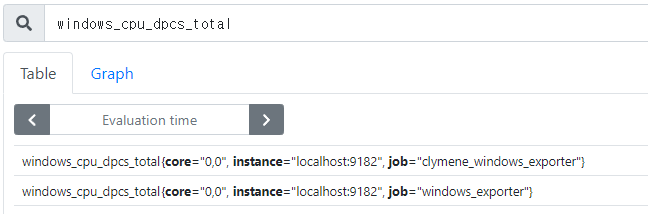
그럼 이제 각각의 Agent들의 성능을 비교해보겠습니다.
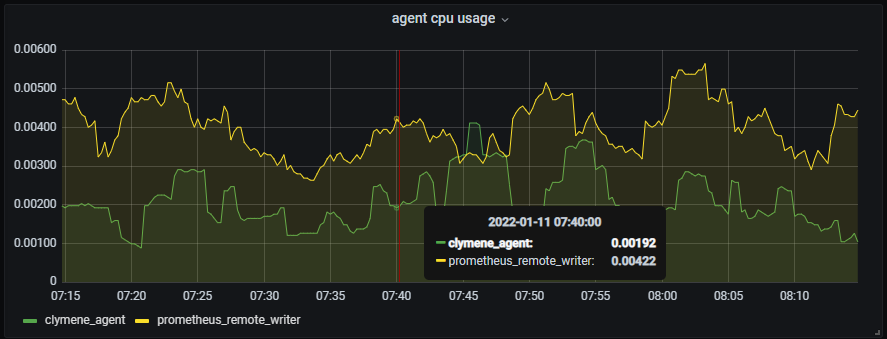
1. cpu 사용량 - Prometheus도 cpu를 많이 사용하지는 않지만, 눈에 띄게 Clymene agent가 더 작은 cpu 사용량을 보이는 것을 확인할 수 있습니다.
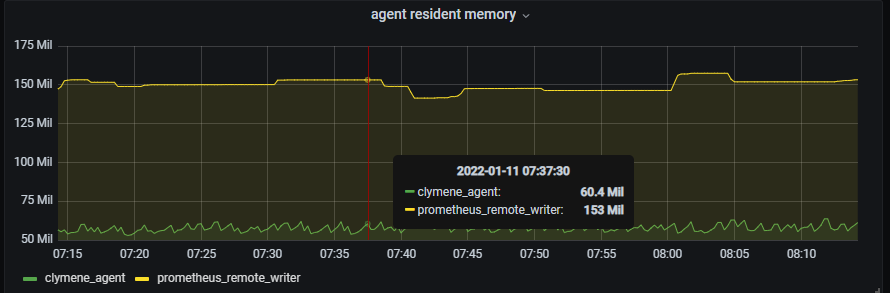
2. Resident memory byte(상주 메모리) - 상주 메모리 사용량의 경우 Clymene와 Prometheus는 두배 이상의 성능차이를 보여주고 있습니다.
3. Virtual memory byte(가상 메모리) - 가상 메모리 사용량의 경우에도 Clymene와 Prometheus는 두배 이상의 성능차이를 보여주고 있습니다.
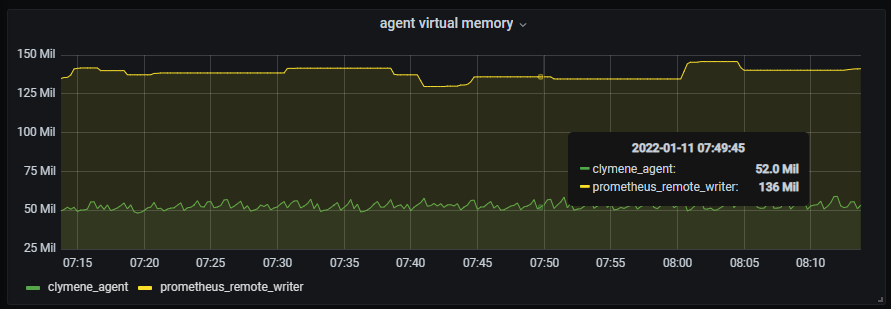
이런 결과가 발생하는 것은 Prometheus의 문제가 아닌, 개발 컨셉의 문제입니다. 설계 초기부터 Agent로 설계되어 적은 리소스 소모량을 보여주는 Clymene-agent와 Prometheus의 remote write의 성능 차이는 어쩌면 당연한 결과가 아닐까 생각됩니다.
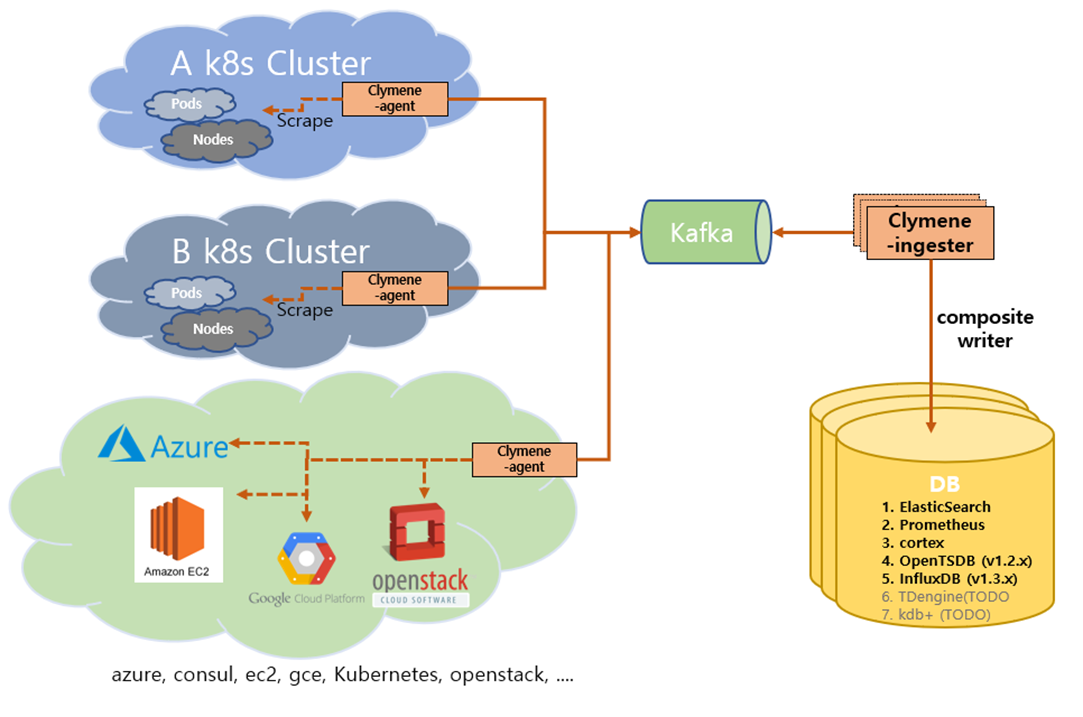
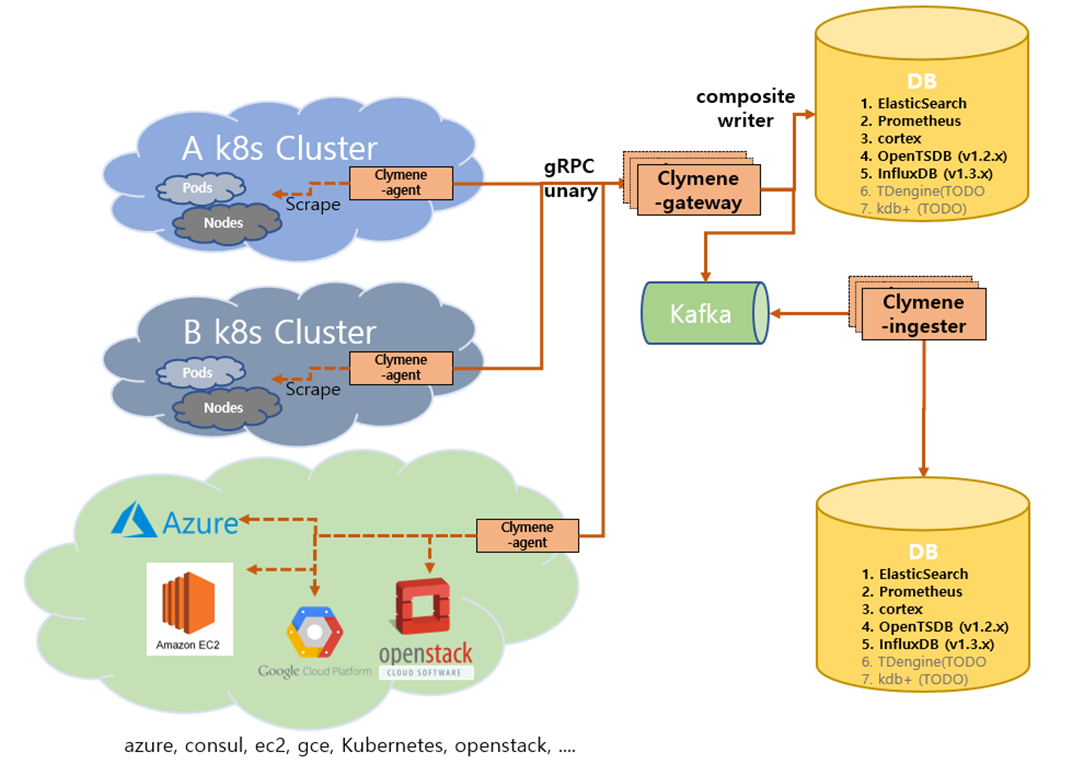
또한, Clymene에는 ingester와 gateway라는 컴포넌트가 존재합니다. 이런 컴포넌트를 이용해 Kafka를 이용할 수도 있으며, gRPC를 이용해 시계열 데이터를 전달받을 수 있습니다. 또한 composite write 기능으로 다양한 farm에 데이터 베이스에 같은 데이터를 저장할 수도 있습니다.
Clymene-ingester와 kafka를 이용한 아키텍처
Clymene-gateway와 ingester를 이용한 아키텍처
여기까지, Clymene 오픈소스를 이용해서 다양한 환경에서의 시계열 데이터를 한 곳에 효율적으로 모으고 관리하는 방법에 대해서 알아보았습니다. 여러분들의 관심만이 Clymene-Project를 발전 시킬 수 있습니다. 많은 관심 부탁드립니다.
감사합니다.
https://github.com/Clymene-project/Clymene
GitHub - Clymene-project/Clymene: the Clymene is a time-series data collection platform for distributed systems.
the Clymene is a time-series data collection platform for distributed systems. - GitHub - Clymene-project/Clymene: the Clymene is a time-series data collection platform for distributed systems.
github.com
'개발 이야기 > 오픈소스' 카테고리의 다른 글
| # 오픈소스 OpenTracing - Zipkin (0) | 2022.03.20 |
|---|---|
| #[Clymene] Efficient time series data collection and management plan in a distributed environment (0) | 2022.01.12 |
| # gRPC - gogoproto extension 사용하기 (1) | 2021.05.30 |
| # gRPC 개요 및 proto 파일 정의 (0) | 2021.05.30 |
| # Jenkins 사용기 (0) | 2021.05.30 |