2022. 3. 20. 00:20 ㆍ개발 이야기/오픈소스
오늘은 OpenTracing 프로젝트 중 Zipkin에 대해서 알아보도록 하겠습니다. Zipkin은 Jaegertracing과 같이 MSA 구조에 특화된 서비스 트레이싱을 할수 있는 오픈소스 입니다. 오늘 다룰 얘기는 Zipkin에서는 기술적으로 어떻게 서비스 트레이싱을 하는지에 대해 알아보도록하겠습니다. OpenTracing이나, Jaeger에 대한 내용은 아래의 링크를 참고해주세요.
https://bourbonkk.tistory.com/84
# 오픈소스 OpenTracing - Jaeger
안녕하세요. 해커의 개발일기 입니다. 오늘은 마이크로 서비스 아키텍처를 사용하여 구축된 응용 프로그램을 프로파일링하고 모니터링하는데 사용하는 Distributed Tracing 분산 추적 기술에 대해서
bourbonkk.tistory.com

Zipkin은 Jaeger보다 먼저 서비스 트레이싱 오픈소스를 주제로 만들어진 오픈소스입니다. OpenTracing에서 만든 규약 덕에 Span과 괕은 데이터 포맷은 Jaeger와 동일하고 전파 방식도 Jaeger와 동일하게 B3-전파 방식을 사용하고 있습니다. Jaeger와 다른점은 프로젝트 언어가 jaeger는 Golang으로 그리고, Zipkin은 java spring으로 작성되었습니다. 그리고 현재는 Jaeger가 더 많은 주목을 받고 있는 것으로 보여집니다. Jaeger는 한번 분석한적이 있기 때문에 이번 포스팅에서는 코드 레벨에서 Zipkin이 어떻게 동작하는지 알아보도록 하겠습니다.
https://github.com/openzipkin/zipkin
GitHub - openzipkin/zipkin: Zipkin is a distributed tracing system
Zipkin is a distributed tracing system. Contribute to openzipkin/zipkin development by creating an account on GitHub.
github.com
먼저 Zipkin을 사용하기 위해서는 Zipkin 라이브러리를 이용해서 서비스 트레이싱을 적용하고자하는 어플리케이션에 코드를 심어주어야 합니다. 지원하는 언어는 아래와 같습니다. go, Java, Ruby 등 Jaeger에서 지원하지 않는 언어도 지원하고 있는 것을 알 수 있으며, 반대로 Jaeger에서 지원하는 언어가 없는 것도 알 수 있습니다. 사용하고자하는 환경에서 사용되는 프로그래밍 언어가 지원되는 서비스 트레이싱 오픈소스를 선택하면 될것 같습니다. Jaeger or Zipkin 중 저에게 선택권이 있다면 저는 Jaeger를 사용할 것 같습니다. Jaeger를 선택한 이유는 Cloud Native에 적합하게 개발되었고, 가볍고, 커스텀하기도 편리하기 때문입니다. 또한, Jaeger는 아직까지 활발하게 개발되고 있습니다.
저에게 익숙한 Go 언어를 이용한 Zipkin 라이브러리 적용을 예시로 들겠습니다. Jaeger의 경우는 Tracer를 생성하면 설정한 환경변수를 이용해 reporter가 생성되는데요. Zipkin의 경우는 reporter를 생성해서 Tracer의 파라미터로 넣어주는 구조를 가졌습니다.
......................
endpoint, err := zipkin.NewEndpoint("echo-service", "")
if err != nil {
e.Logger.Fatalf("error creating zipkin endpoint: %s", err.Error())
}
reporter := zipkinHttpReporter.NewReporter("http://localhost:9411/api/v2/spans")
traceTags := make(map[string]string)
traceTags["availability_zone"] = "us-east-1"
tracer, err := zipkin.NewTracer(reporter, zipkin.WithLocalEndpoint(endpoint), zipkin.WithTags(traceTags))
client, _ := zipkinhttp.NewClient(tracer, zipkinhttp.ClientTrace(true))
if err != nil {
e.Logger.Fatalf("tracing init failed: %s", err.Error())
}
//Wrap & Use trace server middleware, this traces all server calls
e.Use(zipkintracing.TraceServer(tracer))
................이후로는 아래와 같이 계측하고자 하는부분에 span을 생성해주고, 필요한 tag를 붙여주면 되겠습니다.
func traceWithChildSpan(c echo.Context, tracer *zipkin.Tracer) {
span := zipkintracing.StartChildSpan(c, "someMethod", tracer)
//func logic.....
span.Finish()
}이렇게 계측하고자 하는 부분에 코드를 심어주면 해당 부분이 호출될 때마나 span이 생성되며 span.Finish()에서 span 블록이 Zipkin의 백엔드 중 Collector에 전송됩니다. Collector는 아래와 같은 코드를 수행에 데이터를 Cassandra, ElasticSearch, Mysql에 저장합니다.
static final class Factory {
final CqlSession session;
final PreparedStatement preparedStatement;
final boolean strictTraceId, searchEnabled;
Factory(CqlSession session, boolean strictTraceId, boolean searchEnabled) {
this.session = session;
String insertQuery = "INSERT INTO " + TABLE_SPAN
+ " (trace_id,trace_id_high,ts_uuid,parent_id,id,kind,span,ts,duration,l_ep,r_ep,annotations,tags,debug,shared)"
+ " VALUES (:trace_id,:trace_id_high,:ts_uuid,:parent_id,:id,:kind,:span,:ts,:duration,:l_ep,:r_ep,:annotations,:tags,:debug,:shared)";
............................
Input newInput(Span span, UUID ts_uuid) {
boolean traceIdHigh = !strictTraceId && span.traceId().length() == 32;
String annotation_query = searchEnabled ? CassandraUtil.annotationQuery(span) : null;
return new AutoValue_InsertSpan_Input(
ts_uuid,
traceIdHigh ? span.traceId().substring(0, 16) : null,
traceIdHigh ? span.traceId().substring(16) : span.traceId(),
span.parentId(),
span.id(),
span.kind() != null ? span.kind().name() : null,
span.name(),
span.timestampAsLong(),
span.durationAsLong(),
span.localEndpoint(),
span.remoteEndpoint(),
span.annotations(),
span.tags(),
annotation_query,
Boolean.TRUE.equals(span.debug()),
Boolean.TRUE.equals(span.shared()));코드에서 볼 수 있듯 Span에는 trace_id, span_id, span_parent_id, span_tags, span_kind 등 여러 데이터가 존재하는 것을 알 수 있습니다. Span은 서비스 트레이싱에서 가장 작은 데이터 구조로 쉽게 여러 META 정보를 담은 Time 블록으로 이해하면 좋을 것 같습니다. 아래의 그림을 보면 이해가 편할 것 같습니다.
실제는 아래의 그림처럼 데이터가 담기고 있습니다. 큰 그림만 이해해주시면 될 것 같습니다.
사실 서비스 트레이싱에서 보여주는 Trace 데이터는 Span 데이터를 조합해 만든 데이터 입니다. 같은 trace_id를 가진 span 블록들을 조회해서 TimeStamp 순으로 정렬을 하면 트레이스 데이터가 됩니다. Zipkin에서는 서비스명 별 trace_id 정보나 서비스 별 span 정보를 조합해 일부 데이터베이스에 담아두고 있습니다. 이는 조회 성능에 도움을 주기위해 일부 데이터를 만들어 놓는 것입니다. 실제로 span 데이터 조회 코드를 한번 확인해보겠습니다.
final class SelectFromSpan extends ResultSetFutureCall<AsyncResultSet> {
static final class Factory {
..............................................
Factory(CqlSession session, boolean strictTraceId, int maxTraceCols) {
this.session = session;
this.preparedStatement = session.prepare(
"SELECT trace_id_high,trace_id,parent_id,id,kind,span,ts,duration,l_ep,r_ep,annotations,tags,debug,shared"
+ " FROM " + TABLE_SPAN
+ " WHERE trace_id IN ?"
+ " LIMIT ?");이처럼 데이터를 실제 모습을 확인해보면 어떤 방법으로 서비스 트레이싱이 이루어지는지 알 수 있습니다. 여기서 MSA로 개발했을 경우 서비스와 서비스 간 서비스 트레이싱은 어떻게 하느냐? 이 또한 간단합니다. HTTP 통신할 때 헤더에 trace_id를 심어서 전달합니다. 물론 이것도 개발자가 Zipkin 라이브러리를 얼만큼 잘 적용했는지에 따라 달라질 수 있습니다. 이렇게 헤더에 trace_id와 같은 이전 최상위의 Root span 데이터를 심어서 전파하는 방식을 B3 전파방식이라고 합니다.
공식 홈페이지에 있는 Zipkin의 예시 이미지입니다.
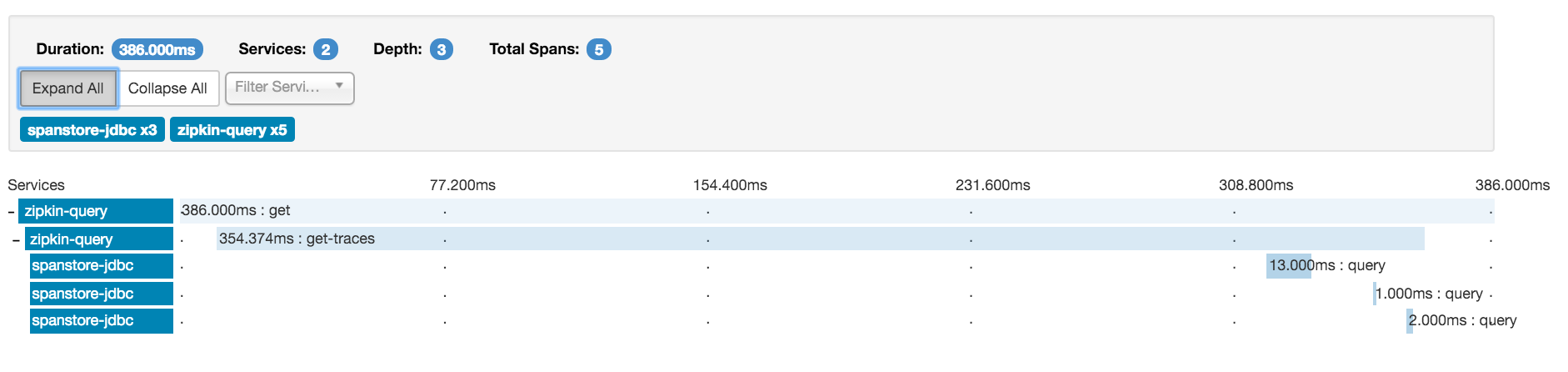
이렇게 Hierarchy(계층 구조)하게 데이터를 그리기 위해서는 위에서 설명한 span 데이터를 잘 조회해 아래와 같이 데이터를 뽑아주면 됩니다. 핵심은 같은 TraceID를 가지고 있고, timestamp 순서에 따라 어떻게 정렬되었는지를 확인하면 될 것 같습니다.
[
{
"traceId": "5982fe77008310cc80f1da5e10147517",
"name": "get",
"id": "bd7a977555f6b982",
"timestamp": 1458702548467000,
"duration": 386000,
"localEndpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
},
"annotations": [
{
"timestamp": 1458702548467000,
"value": "sr"
},
{
"timestamp": 1458702548853000,
"value": "ss"
}
]
},
{
"traceId": "5982fe77008310cc80f1da5e10147517",
"name": "get-traces",
"id": "ebf33e1a81dc6f71",
"parentId": "bd7a977555f6b982",
"timestamp": 1458702548478000,
"duration": 354374,
"localEndpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
},
"tags": {
"lc": "JDBCSpanStore",
"request": "QueryRequest{serviceName=zipkin-query, spanName=null, annotations=[], binaryAnnotations={}, minDuration=null, maxDuration=null, endTs=1458702548478, lookback=86400000, limit=1}"
}
},
{
"traceId": "5982fe77008310cc80f1da5e10147517",
"name": "query",
"id": "be2d01e33cc78d97",
"parentId": "ebf33e1a81dc6f71",
"timestamp": 1458702548786000,
"duration": 13000,
"localEndpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
},
"remoteEndpoint": {
"serviceName": "spanstore-jdbc",
"ipv4": "127.0.0.1",
"port": 3306
},
"annotations": [
{
"timestamp": 1458702548786000,
"value": "cs"
},
{
"timestamp": 1458702548799000,
"value": "cr"
}
],
"tags": {
"jdbc.query": "select distinct `zipkin_spans`.`trace_id` from `zipkin_spans` join `zipkin_annotations` on (`zipkin_spans`.`trace_id` = `zipkin_annotations`.`trace_id` and `zipkin_spans`.`id` = `zipkin_annotations`.`span_id`) where (`zipkin_annotations`.`endpoint_service_name` = ? and `zipkin_spans`.`start_ts` between ? and ?) order by `zipkin_spans`.`start_ts` desc limit ?",
"sa": "true"
}
},
...................생략
데이터의 구조와 프로토콜을 정확하게 파악하고 있으면, 사실 언어는 개발자가 편한 언어를 사용해서 개발하면 됩니다. 서비스 트레이싱의 데이터 구조를 정의한 프로젝트가 OpenTracing이고, 이를 구현한 오픈소스가 Jaeger, Zipkin이 되겠습니다. 서비스 트레이싱을 적용해야 한다면, 사용에 편리한 오픈소스를 사용하면 되며, 데이터 구조를 파악하면 손쉽게 커스텀할 수 있습니다. Zipkin 프로젝트는 지속적으로 개발이 되지 않는 것인지, 프로젝트를 로컬에서 빌드하면 다양한 이슈가 발생하고 몇몇 이슈들은 검색하면 "개인적은 빌드는 지원하지 않는다."는 코멘트를 볼 수 있습니다. 코드 레벨로 세밀한 디버깅을 해보고 싶었지만, 빌드 에러 잡다가 몇 일이 지나 단순한 코드 분석으로 블로그를 마침니다.
새롭게 서비스 트레이싱을 커스텀하거나 도입 예정이신분들은 이런 눈앞에 보이는 문제들을 겪기 싫으신 분들은 Jaeger를 추천해드립니다(물론 이슈의 난이도는 상대적인 것들입니다) 감사합니다.
'개발 이야기 > 오픈소스' 카테고리의 다른 글
| 오픈소스를 이용한 다중 k8s 클러스터 환경의 Node/POD 리소스 사용량과 로그 모니터링 (1) | 2022.08.17 |
|---|---|
| # 오픈소스를 이용한 다중 k8s 클러스터 환경의 모니터링 시스템 구축 (0) | 2022.08.03 |
| #[Clymene] Efficient time series data collection and management plan in a distributed environment (1) | 2022.01.12 |
| #[Clymene] 분산 환경의 효율적인 시계열 데이터 수집 및 관리 방안 (0) | 2022.01.11 |
| # gRPC - gogoproto extension 사용하기 (1) | 2021.05.30 |